08.16.18 By Mohit Garg

 The problem of heavy workloads:
The problem of heavy workloads:
In the simplest term, a workload is the amount of work performed by an application in a given period. Every application has limited capability to handle and process work. When an application is assigned a workload beyond its capability, it may take a long time to complete or often just crashes. It becomes even more severe in cases where a workload requires high compute resources, such as servers or database systems assigned a workload upon creation eg. cloud based applications. Irrespective of platform or industry, the problem of heavy workloads must be addressed efficiently and optimally to ensure project timelines and deliverables are met in a timely manner.
One solution for heavy workload processing and boosting application performance, is to split the workload into smaller chunks on an increased number of servers to carry out parallel execution of the smaller workloads. The shortcoming of this approach is the complexity and cost to setup, maintain and deploy these environments.
This is where Azure batch processing, a tool from Microsoft Azure Services, can both reduce the cost and complexity of running the application in a cloud environment.
Before we get into the details of Azure batch processing and workflows, let’s first review commonly used terminology:
| Account | A Batch account is a uniquely recognized entity within the Batch service. All processing is associated with a Batch account. |
| Compute Node | A compute node is an Azure virtual machine (VM) or Cloud service VM that is dedicated to processing a portion of your application’s workload. |
| Pool | A pool is defined as a collection of nodes which the application runs on. |
| Job | A job is a collection of tasks. It manages how computation is performed by its tasks on the compute nodes in a pool. |
| Task | A task is a unit of computation that is associated with a job. It runs on a node. |
| Workload Application | An application that executes the workload |
| Batch Application | An application that automates the process of creating a pool, job and assigning a task to the job. |
| Node agent SKU | Each node in the pool has the batch node agent running on it. The batch node agent provides the command and authority interface between the node and the Batch service. |
Azure Batch is a robust service that provides parallel batch processing to execute intensive workloads of varying size. It creates a pool of compute nodes (virtual machines) to tackle heavy loads. With Azure Batch, batch processing has become more streamlined and viable to complete data-intensive workloads at any scale.
To initiate automated creation and management of Azure Batch pool, job, and task, the developer needs to create a batch application which can carry out on-premise execution using batch API. The batch application can be easily developed as an Azure CLI script, .Net application, or Python application. The batch application is not limited to any technology as Azure batch service provides REST API which is well documented. The following diagram depicts an Azure Batch Processing design based on a parallel workload:
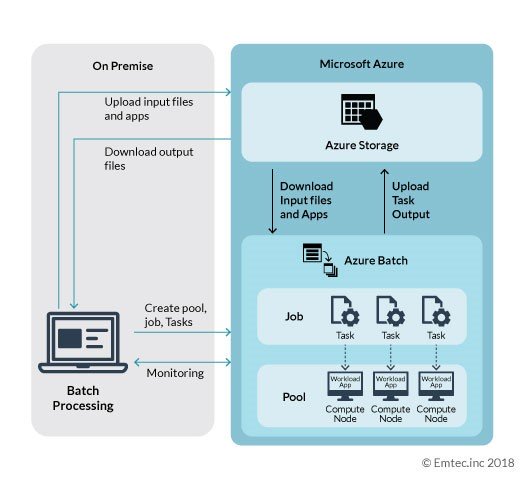
The following steps explain the Azure batch workflow scenario:
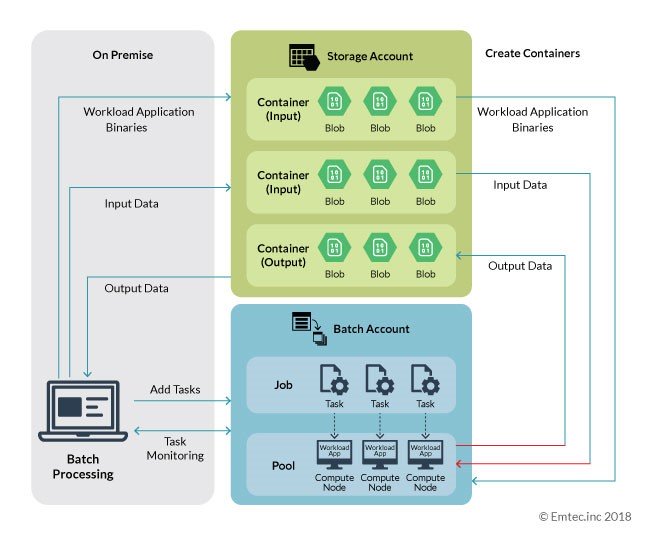 The block diagram above is an extension of the detailed diagram represented in the Azure batch processing section above. The overall execution process is the same, except one special attribute that the workload application is aware of the Cloud. It is capable to execute read and write operations on Cloud storage.
The block diagram above is an extension of the detailed diagram represented in the Azure batch processing section above. The overall execution process is the same, except one special attribute that the workload application is aware of the Cloud. It is capable to execute read and write operations on Cloud storage. Let’s review an example of an application which is not aware of the cloud. Consider this sample project (Ref 2)where an application takes MP4 files from the filesystem and converts them into an AVI format using a FFmpeg tool (which is not Cloud aware) and then saves them to the filesystem.
Let’s review an example of an application which is not aware of the cloud. Consider this sample project (Ref 2)where an application takes MP4 files from the filesystem and converts them into an AVI format using a FFmpeg tool (which is not Cloud aware) and then saves them to the filesystem.The data processing remains same as mentioned in Azure batch processing with the only difference being the tasks act as the intermediate between I/O container and workload application present in the compute node. Azure Batch has the capability to push the file from Cloud storage to the node before starting the task, and after completion of the task, push it back to Cloud storage.
Pool configuration plays a critical role while designing a workload solution in Azure Batch. The right configuration will affect valuation and intricacy of the solution. Based on the nature of the workload application, the following configurations are considered:
| Image reference properties | Example |
| Publisher | Canonical |
| Offer | UbuntuServer |
| SKU | 14.04.4-LTS |
| Version | latest |
The application and its prerequisites need to be installed/pushed after node creation.
Azure batch is a great option to run heavy workloads. Loose coupling of batch configuration makes it easy to migrate existing applications to Azure batch to take advantage of cost-savings. Azure batch also can be used to scale out the execution of R algorithm (Ref 3)*. If you are looking to optimize your costs while ensuring much higher performance with elastic resources, Azure Batch is a great solution. Contact us to get started.


