03.15.18 By Bridgenext Salesforce Team

It’s a word we hear all the time with Einstein Analytics. Key decision makers can perform granular analysis of data through Einstein Analytics’ easy to use dashboards to derive actionable insights.
There are some scenarios where data is fetched from multiple sources to broaden the analysis scope. In this blog, we discuss a reliable method to allow your multiple data sources to keep many-to-many relationships or granularity. We will delve into how you can also utilize the Salesforce Analytics External API to avoid missing rows or even duplicating them in your datasets.
Suppose your organization uses Opportunity Schedules and Opportunity Splits for maintaining the Sales Data for products that your company markets. Your sales management needs reports or dashboards to track the number of bookings each sales representative has made. If you have Einstein Analytics licenses, you can use the custom reporting and dashboards provided by this tool to represent the data.
To view this data, creating a dataset in the Einstein Analytics platform is required where the Opportunity Schedules and Opportunity Splits can be combined. Another option is to keep the data as separate datasets and utilize Salesforce Analytics Query Language (SAQL) to join them together at runtime to view the combined data. Lastly, you can somehow join the two datasets together to combine the data in one dataset.
It is important to understand that if you use these datasets separately, then the uniting logic will happen while you load it to the dashboard. This will reduce the performance of the dashboard as loading time will increase if there is a high volume of data.
When augmenting them together using the data flow to create one single dataset, limitations will lead to joining two objects which have a many-to-many type of relationship between them. When such datasets in Einstein analytics are augmented, the platform provides the option of joining using the ‘LookupSingle’ or ‘LookupMulti’ option.
Both of the above joining options do not guarantee achieving a true form of data as a final dataset. Some records may get skipped for the single type join and when using multi-type the measures for the number of matches found will get added.
A way to resolve the above-mentioned problems or to overcome analytics limitations is by using Apex. The joining logic can be written using Apex code within the Salesforce platform. The combined data can then be sent to Einstein analytics using Analytics External Data Rest API and a final combined dataset can be created there. A scheduler will ensure this logic is executed regularly and the data is sent over to Einstein Analytics systematically.
To accomplish this, a batch class is written in the Salesforce instance using Apex, which will fetch the Opportunity Schedules across the needed time period. Now, the corresponding Opportunity ID can be used to fetch the related Split records and then use them for the loop. The data can be combined to form a comma separated string (CSV). The idea here is to create a CSV dataset which can be sent over to Analytics in an iterative fashion for the creation of the dataset.
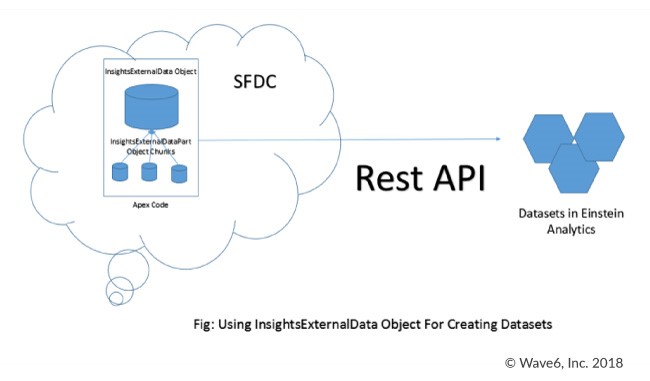
Dataset creation needs metadata, typically in json format. This json file can be uploaded in Salesforce and be used as a reference for creating the actual dataset.
To accomplish this, you would insert the ‘InsightsExternalData’ object after assigning properties like Dataset Name, Format of the data source with ‘Action’ initially set as ‘None’ and the ‘metdataDataJson’ property assigned with the data coming from the above-mentioned metadata creation.
The Start, Execute and Finish methods are used to complete the analytics dataset creation. The start method would fetch the data. The execute method would then create the delimited header as well as data strings with columns comprising of both Schedules and Splits objects, in batches. With the data created for each batch, it is incrementally sent to Einstein analytics using the ‘InsightsExternalDataPart’ object. The finish method will then process the data strings using ‘InsightsExternalData’ creating the dataset in Einstein Analytics.
Organizations can achieve various benefits from this solution, including:
Data is the core of an organization. So, an accurate dataset is imperative. Connecting datasets which are cumbersome can be simplified with Einstein Analytics, providing two methods to create the dataset utilizing data from various sources.
If your organization needs help using Einstein Analytics, contact us today!


